您好,欢迎来到深圳市中晟源科技有限公司
服务热线:0755-83266986


新闻详情



对于微处理界第一颗基于ARM®Cortex®-M7内核的高性能微控制器STM32F7系列,相信很多人对它都不陌生了。比如STM32F7系列微控制器采用90nm工艺,工作频率高达216MHz,采用6级超标量流水线和浮点单元,测试分数高达1000 CoreMarks,性能提升的同时保持高能效,与STM32F4系列管脚高度兼容等等。
一般来讲,基于ARM®Cortex®-M7内核的微控制器大多具有相似的处理器配置选项。通常包括:
-一个64位AXI系统总线接口
-一个指令和数据高速缓存
-64位指令紧耦合存储器(ITCM)
-双32位数据紧耦合存储器(DTCM)
不过,本文只是从应用开发的层面介绍STM32F7系列有别于其它使用Cortex-M7内核的MCU的几个特色。
首先,第一个重要特色在于STM32F7器件同时具有ITCM接口和AXI接口连接到片内闪存,如图1所示。

图1:基于ARMCortex-M7内核的系统级芯片的框图
ITCM和AXI双接口的存在使得执行代码时具备更大的灵活性。此外,STM32F7还有一个称为自适应实时加速器(ARTAccelerator?)的内置闪存加速器,从而实现闪存零等待执行。使用TCM接口和ART加速器能能实现与带缓存AXI接口相似的性能。同时用户代码也不会有高速缓存失效或高速缓存维护操作的麻烦。
利用ART Accelerator加速引擎和高达16kB的L1缓存,STM32F7MCU可实现ARM Cortex-M7的最佳性能。不管是从片内闪存还是外部存储器执行代码,在216MHz下均可达到1082 CoreMark/462 DMIPS。
第二个重大特色在于内部SRAM分布在不同的模块中,以降低动态功耗,并允许从各个总线主机同时访问不同的SRAM模块,以优化带宽和延迟。
此架构的一个典型应用实例就是人机界面,在人机界面中,音频和图形数据与系统RAM之间的传输必须同时进行。
第三个就是它的高级浮点单元。STM32F7系列器件具有一个高性能的单或双精度浮点单元(FPU),支持所有ARM单或双数据处理指令和数据类型。FPU在需要浮点数学精度的许多应用中提供了优势,包括环路控制、音频处理、音频解码和数字滤波等。
它还有个额外优势,那就是将某些功能的执行或处理可以从CPU分流到FPU,使CPU用于其他任务。它支持双精度,因此更易于使用双精度浮点指令的基于PC的数学软件。
第四,STM32F7 MCU最具特色的设计之一是它们的智能系统架构,它使用两个子系统,如图2所示:
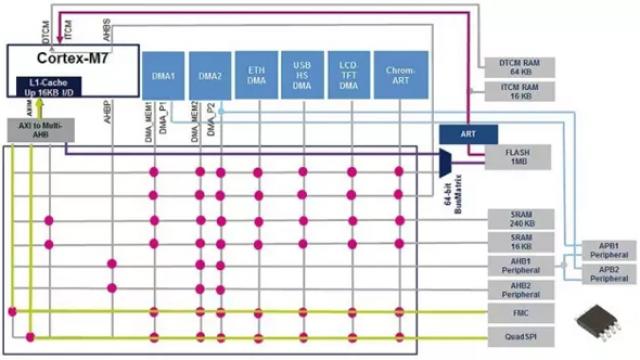
图2:STM32F7微控制器的总线矩阵
AXI-to-multi-AHB桥将AXI4协议转换成AHB-Lite协议
multi-AHB总线矩阵管理主机之间的访问仲裁
该仲裁使用循环调度算法保障主机对从机的访问,即使多个高速外设同时工作,也能实现同时访问并高效运行。
最后,不得不提它的L1高速缓存。STM32F7嵌入了指令和数据高速缓存,当从片上或片外存储器读取代码和数据时可弥补插入等待状态,从而提高性能。当然,如果出现高速缓存失效和高速缓存行填充,此时查看高速缓存将无法保证数据的确定性。
这就是为什么要强烈推荐使用TCM存储器来执行关键代码、存储关键数据的原因。这在必须保证安全操作的应用中(如家电和电机)通常都很有用。
由于高速缓存不仅可以由CPU访问,也可以通过其他主机进行访问(包括直接存储器访问(DMA)控制器),因此需要软件维护操作。访问物理存储器时,这些主机可能会读出过期的数据,而更新的数据在CPU高速缓存中已可用。
为了避免这个问题,开发者编写用户代码时应该采取以下措施:
A.当除CPU以外的主机将执行对高速缓存的访问之前,推荐进行高速缓存清零。这是为了确保CPU的最新的更新数据被写回到物理存储器。
B.当除CPU以外的主机对高速缓存数据进行了更新后,在对高速缓存进行读操作之前,CPU应该使高速缓存失效。这是为了确保从物理存储器的直接读取。
C.有时也需考虑无高速缓存操作。当高速缓冲存频繁被其他主机访问时,可以通过CPU配置不可缓存属性防止数据的不一致性。

